Obsah
Claude Mythos a bezpečnostní audit Firefoxu
Vytvořeno: 16.5.2026 | Aktualizováno: 16.05.2026 14:42
Mozilla popsala, jak při hardeningu Firefoxu zapojila Claude Mythos Preview a další AI modely do hledání latentních bezpečnostních chyb. Příspěvek Min Choie na X k tomu dobře vystihuje hlavní pointu: AI audit kódu už není jen marketingová ukázka, ale prakticky použitelná metoda pro hledání reálných zranitelností.

Co se stalo
Mozilla uvádí, že v rámci Firefoxu 150 opravila 271 chyb identifikovaných pomocí Claude Mythos Preview. Z těchto 271 chyb bylo 180 hodnocených jako sec-high, 80 jako sec-moderate a 11 jako sec-low.
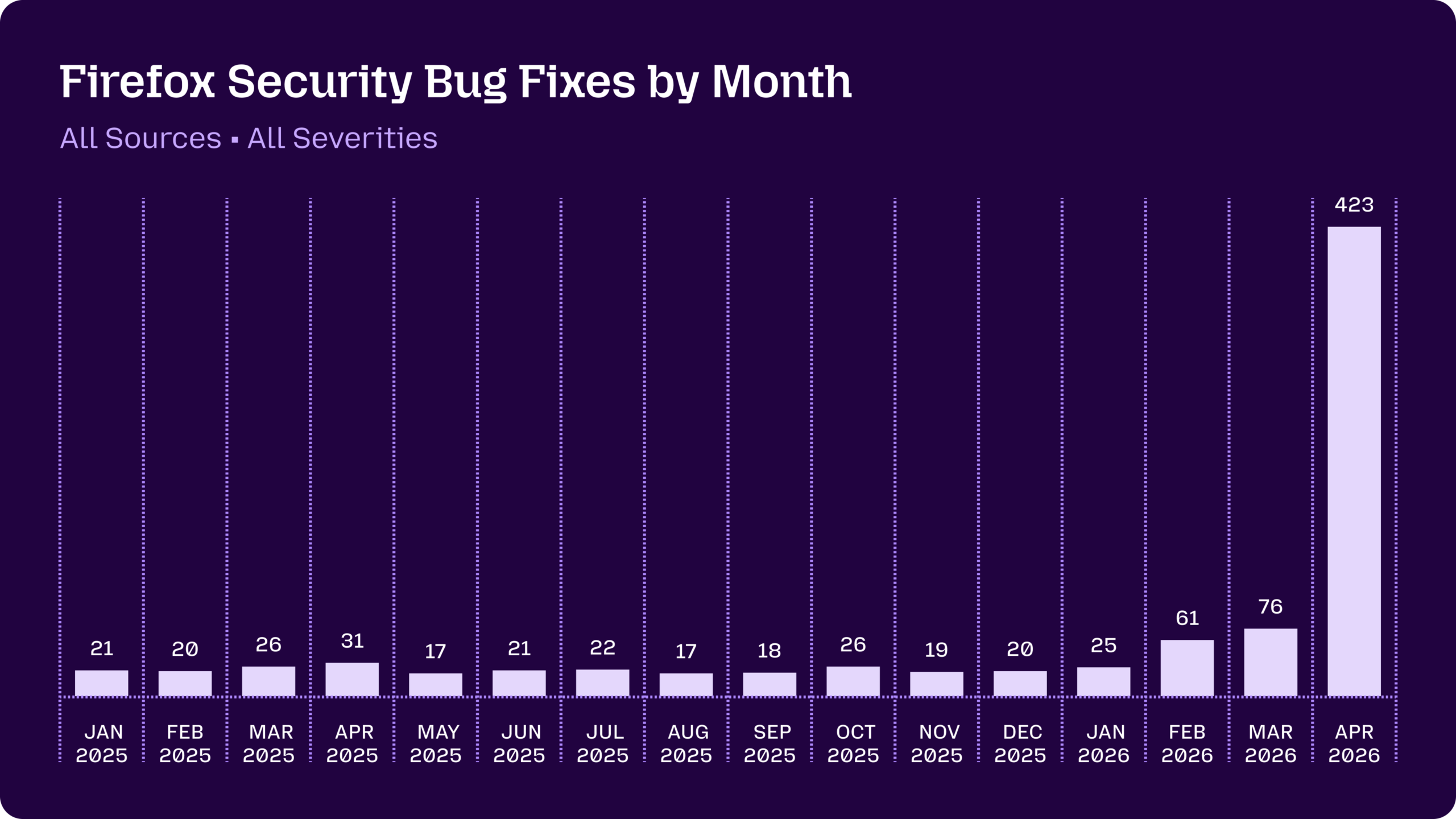
Důležité je, že dubnových 423 opravených bezpečnostních chyb není totéž jako „423 chyb nalezených Mythosem“. Mozilla v FAQ vysvětluje, že do dubnového čísla patřilo:
- 271 dříve oznámených chyb spojených s Claude Mythos Preview,
- 41 externě reportovaných chyb,
- 111 dalších interně nalezených chyb — zhruba rozdělených mezi stejnou AI pipeline s Mythosem v jiných releasích, jiné modely a jiné techniky jako fuzzing.
Proč je to zajímavé
Graf z článku ukazuje prudkou změnu objemu bezpečnostních oprav. V roce 2025 se měsíční počty bezpečnostních oprav Firefoxu držely přibližně v rozsahu 17–31. V roce 2026 následoval nárůst na 61 oprav v únoru, 76 v březnu a 423 v dubnu.
To neznamená, že by samotný model magicky opravil Firefox. Zásadní je kombinace modelu, harnessu a interní bezpečnostní pipeline. Mozilla popisuje posun od dřívějších LLM reportů plných šumu k agentnímu procesu, který umí nejen navrhnout hypotézu zranitelnosti, ale také vytvořit a spustit reprodukovatelný test case.
Jak fungoval přístup Mozilly
Mozilla postavila vlastní harness nad existující fuzzing infrastrukturou. Smyslem nebylo jen staticky „přečíst kód“, ale dynamicky ověřovat hypotézy o zranitelnostech.
Zjednodušený proces:
- Vybere se oblast kódu nebo konkrétní soubor, kde má model hledat problém.
- Model dostane úlohu ve stylu: v této části kódu je chyba, najdi ji a vytvoř test case.
- Harness umožní modelu test case vytvořit a spustit.
- Výsledky se sbírají z více paralelních běhů na dočasných VM.
- Následuje deduplikace, triage, založení bugů, oprava, testování a vydání fixů.
Mozilla zdůrazňuje, že model je jen jedna část systému. Aby to fungovalo ve velkém, musí být napojený na konkrétní procesy projektu — bug tracker, bezpečnostní klasifikaci, release management a práci vývojářů.
Typy chyb
Ve zveřejněném vzorku jsou chyby z různých částí browseru: WebAssembly GC, DOM, IndexedDB, IPC, WebTransport, DNS/ECH parsing, XSLT nebo sandboxing. Zajímavé je, že část reportů míří na sandbox escapes — tedy chyby, které samy o sobě obvykle nestačí na plný kompromis prohlížeče, ale mohou být součástí exploit chainu.
Mozilla zároveň upozorňuje, že označení sec-high nebo sec-critical neznamená automaticky praktický exploit. V prohlížeči s obranou ve vrstvách je často potřeba zkombinovat více zranitelností, například nejprve kompromitovat sandboxovaný content proces a teprve potom eskalovat do privilegovaného parent procesu.
Co z toho plyne
- AI audit kódu se posouvá z experimentu do praxe. Nejde jen o chatovací odpovědi nad zdrojákem, ale o agentní smyčku s testy a reprodukcí.
- Největší hodnota je v pipeline. Samotný model nestačí; je potřeba orchestrace, běhové prostředí, filtrování šumu a integrace do bezpečnostního lifecycle.
- Nové modely zvedají účinnost celé pipeline. Mozilla uvádí, že po vybudování end-to-end systému je relativně jednoduché model vyměnit a získat lepší výsledky.
- Fuzzing a AI se doplňují. AI analýza se ukázala jako silná hlavně tam, kde je potřeba reasoning přes složité subsystémy, IPC a sandboxové hranice.
- Tlak se přesune i na útočníky. Pokud obránci dokážou podobné pipeline nasadit, je pravděpodobné, že podobné schopnosti budou používat i útočníci.
Praktická poznámka pro vlastní projekty
Pro menší projekt není realistické kopírovat celou infrastrukturu Mozilly. Přenositelný je ale princip:
- nezačínat obecným „najdi bugy v repo“,
- vybrat rizikovou část kódu,
- dát modelu možnost spouštět testy,
- požadovat reprodukovatelný test case,
- oddělit spekulace od ověřených nálezů,
- napojit výstup na normální triage a opravy.
Mozilla tento základní vnitřní loop shrnuje velmi jednoduše: v této části kódu je chyba, najdi ji a postav test case.
{kind=link}